深入理解 Java 线程池:原理、动态调整与监控实践
深入理解 Java 线程池:原理、动态调整与监控实践
“当你在系统高并发场景下陷入崩溃边缘的时候,线程池也许就是你最靠谱的救命稻草。”
在面试中,Java线程池往往是被反复拷打的高频知识点。本文将系统性地带你梳理线程池的核心原理、关键参数、拒绝策略、动态调整以及如何实现一个简单的监控机制,帮你从“线程焦虑症”中走出来。
一、为什么线程的创建和销毁开销大?在 Java 中,每个线程对应一个 内核级线程,也就是说 JVM 的线程模型是 一对一(1:1) 的。创建一个线程就需要调用操作系统接口进入内核态,完成资源分配、栈空间初始化等操作;销毁线程同样需要系统调用释放资源。
这意味着:
线程的创建和销毁属于“重量级”操作;
如果频繁地 new Thread,会严重拖慢系统性能。
从 JDK 21 开始,虚拟线程(Virtual Thread) 登场。它基于用户态调度,具备“多对多”的线程模型(多个虚拟线程映射到少量内核线程上),大大降低了线程创建的成本。但现实是——许多项目仍运行在 Java 8、11,因此我们仍需认真对待传统线程池。
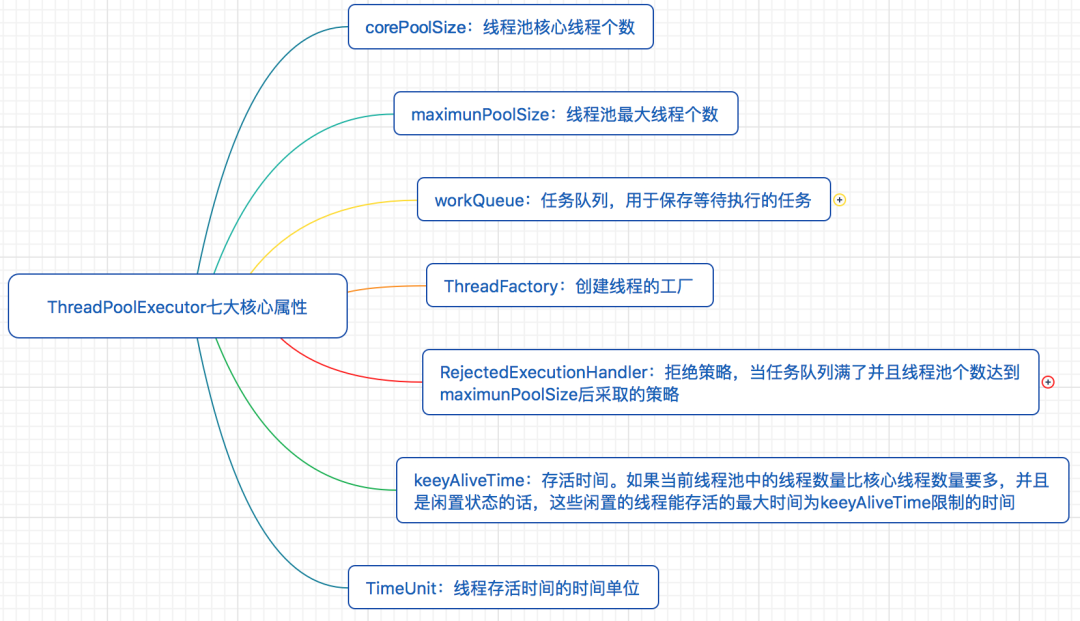
二、线程池的诞生:复用、管理、隔离为了解决线程频 ...

从 0 设计一个短链接服务:如何实现尽可能短、可变长的短网址系统?
从 0 设计一个短链接服务:如何实现尽可能短、可变长的短网址系统?在日常生活中,我们经常在短信、微博、广告营销中看到“短链接”,如:
12https://t.cn/EXaQ4xYhttps://bit.ly/3Yp9zJk
相比冗长复杂的原始 URL,短链接不仅更美观、更易传播,还能用于追踪分析和跳转控制。那么问题来了:
如果你是系统设计者,如何从零构建这样一个短链接服务,满足“尽可能短、随着使用量增加再变长”的需求?
🧠 1. 问题分析:我们要解决什么?
输入一个长链接,返回一个唯一且尽可能短的短链,且短链可以反向还原长链。
系统设计核心目标:
✅ 短链接越短越好(前期尽量短,后期按需增长)
✅ 能还原原始长链接
✅ 能支持高并发、高访问量
✅ 保证唯一性、稳定性
❗提示:不能直接用 MD5、SHA1,它们生成的都是固定长度(通常32~40位)的字符串,不满足“尽量短、可变长”的要求。
💡 2. 设计思路:唯一 ID + 可变 Base62 编码我们采用如下经典架构:
📌 方案核心:唯一 ID + Base62 编码
为每个长链接生成唯一 ID(如自增 ID ...
深入理解 ConcurrentHashMap:JDK 1.7 与 1.8 的演进与实现原理
深入理解 ConcurrentHashMap:JDK 1.7 与 1.8 的演进与实现原理在高并发场景中,ConcurrentHashMap 作为 Java 提供的线程安全的哈希表实现,被广泛应用于缓存、连接池、线程计数等业务中。它的高性能来源于底层的数据结构与锁机制的优化。本文将带你一步步深入了解 JDK 1.7 和 1.8 中 ConcurrentHashMap 的实现原理、区别以及背后的技术设计。
一、JDK 1.7:分段锁机制(Segment Lock)在 JDK 1.7 中,ConcurrentHashMap 的核心设计理念是分段锁机制(Segment Locking)。其结构如下:
✳️ 数据结构解析:
整体结构:由一个数组 Segment[] 组成,每个 Segment 是一个哈希表 HashEntry[]。
锁粒度:每个 Segment 内部使用 ReentrantLock 锁,意味着多个线程只要访问的是不同 Segment,可以并行执行。
默认分段数:16(可配置),最多支持 16 个线程同时写操作。
✅ 优点:
通过锁分段降低锁竞争,提升并发性能;
避免了全表加 ...
TCP 与 UDP 协议详解:原理、区别与应用场景全解析
TCP 与 UDP 协议详解:原理、区别与应用场景全解析在日常使用网络的过程中,我们经常听到 TCP 和 UDP 这两个词。你打开网页、发送消息、观看视频,背后都在使用 TCP 或 UDP 进行数据传输。那么这两个协议到底是怎么工作的?它们之间有哪些区别?适用在哪些场景?本文将带你一步步深入了解它们的工作原理和核心差异。
一、TCP 和 UDP 协议是什么?TCP(Transmission Control Protocol) 和 UDP(User Datagram Protocol) 都是工作在 传输层(Transport Layer) 的协议。它们的目标相同——实现两个应用程序之间的数据传输。
无论是文字、图片还是视频,在 TCP 和 UDP 看来,都是一堆二进制数据。因此它们并不关心数据内容的“意义”,而是关注“怎么把数据安全、快速地传送到对方”。
二、什么是连接与非连接?这两个协议最大的不同在于:
TCP 是基于连接的协议,UDP 是基于非连接的协议。
什么意思呢?我们用一个简单的类比来说明:
TCP 像打电话:你拨号、对方接听、双方确认连接成功后开始通话,通话结束时还 ...
一文彻底搞懂 AQS 的实现原理与设计思想
一文彻底搞懂 AQS 的实现原理与设计思想在面试中,AQS(AbstractQueuedSynchronizer)是一个常见的高频问题。面试官一问“你了解 AQS 吗”,你脑海里只蹦出几个词:“CAS”、“state”、“等待队列”,再深一点就答不上来了。如果让你亲自设计一个并发工具类,你可能连思路都没有。
别急,今天我们就从“如果你要自己实现一个并发工具类”这个角度出发,一步步拆解 AQS 的设计逻辑,并理解为什么它要这么做,为什么这么设计。
什么是并发工具类?实现一个并发工具类要解决什么?所谓并发工具类,就是多个线程能安全访问共享资源的工具。
你得考虑几个核心问题:
如何判断共享资源是否正在被其他线程访问?
如果资源已被占用,新来的线程该怎么办?等?让?走?
如何管理多个等待线程?
如何在资源释放后有序地唤醒它们?
一、用 state 表示资源占用状态最基础的思路就是:用一个变量 state 表示资源状态。
state = 0:资源空闲
state = 1:资源已被某个线程占用
那你可能会问:为啥不用 boolean 呢?
那是因为有些资源支持多个线程同时访问(比如信号 ...

剖析悲观锁与乐观锁:从宏观概念到CAS的微观实现
从面试官的角度深入理解悲观锁与乐观锁
简历就是秒杀项目,高并发高可用,面试一问悲观锁和乐观锁是啥,你绞尽脑汁想了半天就蹦出几个词…
相信很多程序员都有过这样的经历:简历上写着”精通Java”、”精通高并发”、”精通JUC”,但面试时被问到悲观锁和乐观锁的具体实现时,却支支吾吾说不出个所以然。今天我们就来深入剖析这两个重要概念。
什么是悲观锁?悲观锁的核心思想很简单:悲观地认为如果不严格加锁,那么多线程执行一定会出问题。
因此,悲观锁的策略是:
每次访问共享资源都必须加锁
线程必须获得锁之后才能正常执行
如果获取不到锁,线程就阻塞等待
悲观锁确实好使,但它也确实慢。为什么慢呢?
大量读操作场景:如果程序中存在大量的读操作,实际上没有必要每次读的时候都加锁
同步代码块执行时间短:如果同步代码块执行的时间非常短,远小于线程阻塞切换的时间,那加锁就得不偿失了
乐观锁:不加锁的解决方案那有没有一种方法可以不加锁就对多线程访问共享资源做出限制呢?有!这就是乐观锁。
CAS(Compare And Swap)就是乐观锁的一个经典实现。
CAS的工作原理让我用一个生动的例子来解释CAS的工作 ...
深入理解 synchronized:锁升级全解析
深入理解 synchronized:锁升级全解析信不信我花几分钟时间就能让你彻底搞懂 synchronized?很多人一听面试官问 synchronized,绞尽脑汁也只记得几个词:什么无锁、偏向锁、轻量级锁、重量级锁,却根本说不清为什么要做锁升级,为什么要有偏向锁、轻量级锁,甚至连“锁监视器”是什么都不清楚。
简历上写着“精通 Java、高并发编程”,但若不能清晰讲出这些概念,那就是纸上谈兵。那么想讲清楚 synchronized,你必须从 计算机体系结构的发展史 说起。
一、为什么要有 synchronized?计算机发展过程中,CPU 的速度越来越快,但内存的速度相对较慢。为了缓解 CPU 和内存速度不一致的问题,产生了 多级缓存(L1、L2、L3):
L1 和 L2 缓存是 CPU 核心私有的;
L3 缓存是多个核心共享的。
那么问题来了:
在 多线程并发环境下,线程 A 运行在某个 CPU 核心上,把内存的数据读到缓存中并修改,但还没同步到主存;而线程 B 从主存读数据,就会读到旧值。这就是著名的 可见性问题。
此外,还有 指令重排序问题:为了性能,CPU 或编译器可能会 ...

从面试懵逼到通透掌握:分布式锁原理全解(附Redisson与Redlock机制剖)
从面试懵逼到通透掌握:分布式锁原理全解(附Redisson与Redlock机制剖析)你是不是也有这样的经历?
简历上写着“精通 Java,精通 Redis,熟悉高并发场景”,结果一面下来,分布式锁怎么实现?Redisson是怎么加锁的?看门狗机制了解吗?锁丢失你知道怎么解决吗?全程“啊能能”,频频磕巴。
本文不整虚的,带你从0到1,一步步真正搞懂分布式锁的原理与落地实践,面试高频,架构核心,不能不会。
一、什么是“锁”?本质很简单,锁的核心是互斥性:
一个线程拿到了锁,其他线程就不能进入,必须等这个锁被释放后才能继续。
分布式锁本质也是为了实现跨进程、跨节点的互斥执行。
二、最简单的分布式锁实现:SETNX 命令使用 Redis 实现分布式锁的基本思路是:
1SETNX lock_key thread_id
只要返回 1,说明加锁成功。否则说明其他线程已经获得锁,当前线程就拿不到。
1. 加锁后要能解锁不能光会加锁,还要能安全地解锁。那是不是直接执行 DEL lock_key 就可以了?
⚠️ 错!这样会有误删他人锁的风险。
必须先判断锁是否是自己加的,再删除,需要两步操作, ...

深入理解JVM垃圾回收机制,带你一步步思考理解,告别死记硬背!
深入理解JVM垃圾回收机制,带你一步步思考理解,告别死记硬背!今天来专门聊一聊JVM中的垃圾回收机制。
垃圾回收主要针对的是JVM的堆内存,它分为新生代和老年代。
首先需要先对堆有一个大致的认识,堆分为新生代和老年代,在Jdk1.7以前还有一个永久代,它在方法区里,里面存储了我们的class信息、静态变量、常量池等。不过从JDK1.8开始,方法区的实现发生了该改变,取消了永久代的概念,并且在内存上与老年代不再是物理上连续的。方法区包含在元空间中,并直接存储在机器内存中,这么做的目的是使内存溢出的可能性进一步减小,它的空间大小更容易进一步扩展。同时,方法区也将一部分变量转移了出去,比如类的静态变量、字符串常量池都放到了堆内存当中。
如下图所示:
在堆内存中,从垃圾回收的范围上说,一般分为两种:针对新生代的 minorGC(也叫YoungGC) 和 针对老年代的 majorGC(也叫fullGC)。
下来来说明一下GC中一些常见的搜索算法和回收算法。
首先,我们肯定要先标记出回收的对象,也就是哪些是”垃圾”,大概有两种方法:
引用计数法
每个对象有一个引用计数器,每当有一个引用指向它 ...

由浅入深带你快速理解Mysql内部机制!(带面试题补充)
由浅入深带你快速理解Mysql内部机制!(带面试题补充)基础MySQL的执行流程是怎么样子的
连接器:建立连接,管理连接、校验用户身份
查询缓存:查询语句如果命中查询缓存则直接返回,否则继续向下执行。MySQL8.0已删除该模块
解析SQL:通过解析器对SQL查询语句进行词汇分析、语法分析,然后构建语法树,方便后续模块读取表明、字段、语句类型
执行SQL:
预处理阶段:检查表或字段是否存在;将select *中的*符号扩展为表上所有的列。
优化阶段:基于查询成本的考虑,选择查询成本最小的执行计划
执行计划:根据执行计划执行SQL语句,从存储引擎读取记录,返回给客户端
索引为什么MySQL使用B+树作为索引?1. 高效磁盘读写:
B+树节点大小通常等于磁盘页大小,减少磁盘I/O次数。
非叶子节点仅存索引,叶子节点存数据,提高存储密度。
2. 范围查询性能高:
叶子节点双向链表****相连,顺序遍历高效,适合范围查询(如BETWEEN语句)。
3. 结构稳定且自平衡:
B+树自动平衡树高,查找、插入、删除的时间复杂度为 **O(**log **n)**。
更新操作简单, ...